Websiten whereonthe.net kan tracke et billede, og give et bud på, hvordan det er blevet spredt på nettet og via hvilke sites. 100% pålidelig er den vist ikke, men det kan alligevel afsløre nogle pointer omkring billeder og brug af dem.
Man søger på whereonthe.net ved at taste urlen til et billede ind på websiten. Derefter søger siten efter kopier af billedet – eller af billeder, der ligner. Det er selvfølgelig via “billeder, der ligner” at en del af usikkerheden kommer ind.
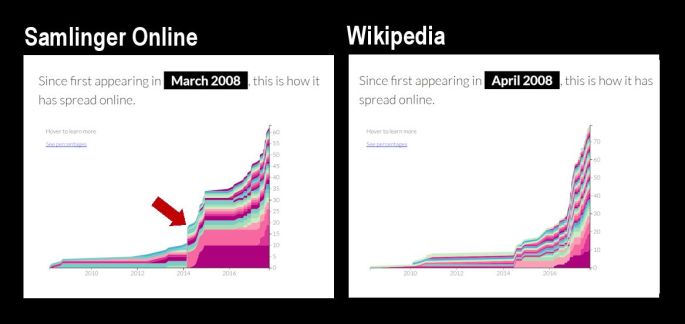
Jeg har prøvet med Solvognen. Udfordringen er, at billeder af en museumsgenstand, ofte fotograferet fra samme vinkel, ligner hinanden temmelig meget. Det er sandsynligvis derfor, at et konkret foto fundet på en bestemt site, kan optræde på nettet længe før siten blev oprettet.
Men sammenstilningen viser også et ret markant hop med efterfølgende stigning i 2014. “Hoppet” findes på analysen af begge sites, men mest tydeligt på Samlinger Online. Det var i efteråret 2014, at Nationalmuseet frigav en stor mængde fotos, og lancerede den første “rigtige” version af museets billedsite. Det er her, at spredningen for alvor starter, og det er fortsat lige siden.
Hvis man ønsker at ens samlinger skal være i spil, kunne nå mange mennesker og bruges af dem, ser frigivelse og afkommerciallicering jo ud til at virke :-)
Det varer måske ikke så længe, før vi alle sammen kan få brug for at modellere i 3D. Hvis man interesserer sig bare en lille smule for VR, AR og MR kan det være svært ikke at få lyst til lidt “gør-det-selv”. Jeg har prøvet online-tool´en Smoothie-3D.
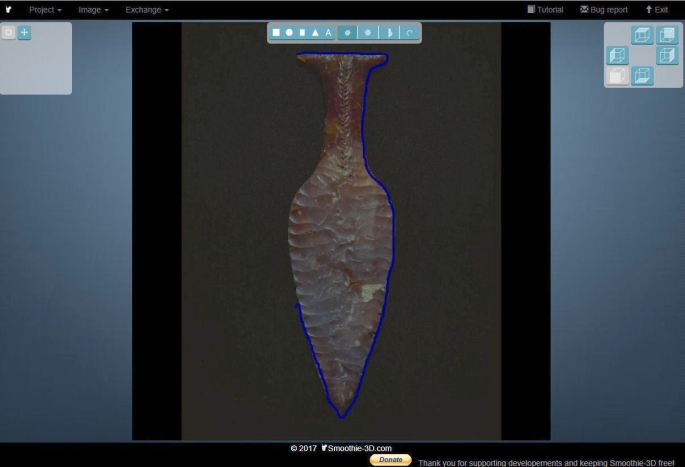
Det særlige ved Smoothie-3D er – udover at det er gratis – at værktøjet gør det nemt at skabe 3-dimensionelle modeller ud fra et foto. Jeg valgte at gøre forsøget med Hindsgavldolken (efter først at have prøvet med en Solvogn – resultatet er ikke for svage sjæle). Man uploader ganske enkelt et foto af det objekt, man ønsker at skabe og tegner derefter rundt om det, som vist nedenfor:
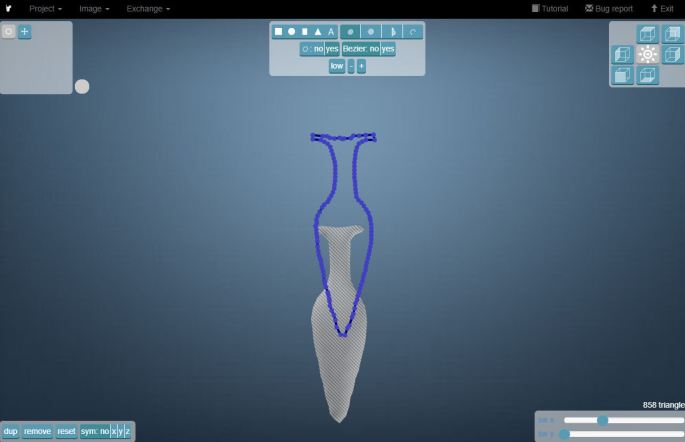
Når genstanden er tegnet op, kan baggrunden fjernes hvorefter modellen roteres og justeres i det 3-dimensionelle rum. Justeringen sker med brug af en linje, bestående af små punkter, der flyttes i forhold til hinanden. Punkterne kan flyttes frem og tilbage, indtil man er helt tilfreds med modellens udseende:
Derefter gemmes modellen, og den kan nu downloades i forskellige formater, .obj, .stl og vrml2. Da jeg prøvede, var det dog kun muligt at downloade i .obj og kun efter genstart af Chrome.
Filformaterne har mange forskellige anvendelsesmuligheder. De kan importeres i andre 3D-modelleringsprograner, som fx Blender , der er et gratis, og temmeligt avanceret program til modellering:
I dette – eller andre programmer, som kan importere fx .obj-formatet, kan man derefter modellere videre og perfektionere sin model yderligere. En god mulighed er også online-modelleringssitet Sculptfab, som har de væsentligste funktioner og er mindre kompliceret end Blender.
Og så kan man naturligvis dele. Min Hindsgavldolk er uploadet til Sketchfab, et online community for deling af 3D-modeller. Den er ganske vist ikke særligt pæn og mangler indtil videre tekstur, men måske har en anden lyst til at arbejde videre med den.
At skabe og dele 3D-objekter kunne godt være et interessant felt for museer, i hvert fald for dem, der har ønsker at øge kendskabet til deres genstande og viden digitalt. Et måske ikke så vildt gæt er, at ønsket om mulighed for adgang til frie modeller af 3dimensioneller genstande i offentligt eje om få år vil være lige så markant som ønsket om at kunne finde og bruge fx fotos er i dag.
Hvis delte 3D filer også let kan hentes til (ikke al for langsom!) print, vil kulturgenstande kunne bruges på uendeligt mange – sjove, spændende og kreative måder. Også selvom det store, kulturhistoriske Thingiverse, som jeg drømte om for 3 år siden lader vente på sig.
Forleden præsterede Europeana “kunstkanalen” Europeana280 med bidrag fra 29 lande – herunder en række danske kunstmuseer. I alt 22 værker er med fra Danmark. Det fik mig til at overveje noget, som jeg har tænkt over gennem længere tid. Hvorfor er der mon så stor forskel på, hvilke institutioner, der digitaliserer og tilgængeliggør deres samlinger, og hvilke der ikke gør?
Europeana280 er et kunstprojekt og derfor er det naturligt nok kunstmuseer, der er med. Fx Skagens Museum, Statens Museum for Kunst og flere andre. 14 museer i alt har bidraget, nogle med flere værker, andre med få – og det er alletiders. Der er selvfølgelig forskel på, hvor mange ressourcer en institution kan lægge i forskellige projekter. Også når det gælder den formidling, der sker via digitalisering og tilgængeliggørelse.
Det er kun brøkdele af museernes samlinger, der er udstillet – og gennem digitalisering kan langt flere få glæde af indholdet. Det samme gælder andre kulturinstitutioner, og tager man et kig på Det Kongelige Biblioteks digitaliseringsoversigt, er det tydeligt, at nogle institutioner har lagt sig klart i spidsen, når det gælder digital adgang. Jeg har plukket nogle stykker ud:
Rigsarkivet
Ca. 18 millioner brugerskabte poster i Dansk Demografisk Database (CC0)
Ca. 30 millioner sider fra historiske dokumenter (CC0)
Online-registratur over samlingerne (CC0)
Bidrag til APEX
Statsbiblioteket
Ca. 32 mio. sider fra danske aviser i Mediestream (omfattet af alm. ophavsret)
Statens Museum for Kunst
Ca. 35.000 gratis værker (heraf ca. 160 “mesterværker” i særligt høj kvalitet, CC0)
Bidrag til Wikipedia, Google Art Project og Europeana
Nationalmuseet
Ca. 30.000 gratis foto af genstande m.m. (CC0, CC-BY og CC-BY-SA)
Ca. 65.000 personer i Modstandsdatabasen
Bidrag til Wikipedia, Google Art Project og Europeana (godt nok kun 1 foto til kunstprojektet)
Det Danske Filminstitut
Ca. 4.000 filmplakater (omfattet af alm. ophavsret)
Ca. 1.000 spillefilm frem til 1928 (“registratur” med klip) (PD eller DFI ejer rettigheder)
Ca. 1.000 stumfilmprogrammer (CC0)
Ca. 500 klip fra dokumentarfilm (BY-SA-NC)
Museet for Søfart
35.359 billeder med relation til museets emneområde (BY-SA-NC)
Museum Sønderjylland
40.000 fotos med relation til regionens historie (Kontakt museet for brug?)
Odense Bys Museer
10.000 billeder, tegninger m.m. fra byen (CC-BY-NC)
Anderseniania: 253 portrætter, 111 papirklip, 2 billedbøger, 251 tegninger, 20 eventyrmanuskripter, 131 udvalgte eventyrbøger på lige så mange sprog, og 250 bøger med HCA’s egenhændige dedikationer. (CC-BY-NC)
Der er et par stykker, jeg ikke har kunnet finde, fx Aros, Moesgaard og Arken, så hvis nogen har tal herfra, vil jeg selvfølgelig indføre dem.
Det er temmelig tydeligt, at Rigsarkivet, der nærmest er en lilleput mht. fysiske besøgstal, vokser til en kæmpe, hvis man ser på institutionen med de digitale briller på. Det hører med, at arkivet har flere millioner brugere på tjenesterne årligt og hertil kommer brugere på 3. parts tjenester, som viser arkivets materialer. Statsbiblioteket tilbyder også millioner af digitaliserede sider. Blandt museerne har hhv. Nationalmuseet og Statens Museum for Kunst digitale samlinger, men har også arbejdet med at få materialerne i brug på flere platforme. Mange mindre museer og arkiver har efterhånden også rigtigt gode, digitale tilbud.
Men hvad er det, som bevirker, at man digitaliserer? Nogle af institutionerne har dét tilfælles, at de har mindre fokus på fysisk besøg som “relevansparamenter”. Det gælder fx Rigsarkivet og Statsbiblioteket – og måske til en vis grad også Nationalmuseet og Statens Museum for Kunst, idet digitaliseringsprojekterne her er startet i perioden, hvor der var genindført gratis adgang til de fysiske udstillinger. Men noget lignende er næppe gældende for flere af de andre institutioner. En del er finansieret via eksterne midler som særlige projekter. Og nogle – men her er jeg ikke helt sikker – er vist påbegyndt i perioder, hvor museet har været under ombygning eller lignende. Digitalisering som led i ombygning og revitalisering kendes også fra museer som Cooper Hewitt og Rijksmuseum.
Hvilke mekanismer resulterer i interesse for at bidrage til skabelsen af mere digital kulturarv? Hvis vi kan identificere incitamenter og hindringer nøjere, kan vejen måske banes for mere adgang til de store mængder af materiale, som ellers kun sjældent bringes ud af museumsarkiver og magasiner. Er det “kun” penge, der skal til? Eller er der også andre faktorer, som spiller ind?
Vi er vant til, at pdf dokumenter er pæne, og fint layoutede – men også lidt kedelige og statiske. Sådan er det ikke mere.
Tidligere var der ikke de samme formidlingsmæssige muligheder i pdf som i fx HTML5 eller i flash, som var meget populært for nogle år siden. Men pdf kan godt indeholde meget dynamiske elementer, og dermed give nye muligheder for både formidling og forskning.
På Kulturhistorisk Museum i Oslo er der gennem et stykke tid gjort forsøg med 3D-scanning af genstande fra Oseberg-fundet. De norske museumsfolk står overfor dén udfordring, at de konserveringsmetoder, som blev brugt for ca. 100 år siden, da skibet og dets indhold blev fundet, har været utilstrækkelige. Den alunkonservering, som man brugte den gang, betyder at genstandene i dag nedbrydes indefra (Kulturhistorisk Museum har en lidt længere beskrivelse for konserveringsinteresserede)
Der arbejdes naturligvis på at finde en løsning for genstandenes fortsatte bevaring. I forbindelse med dette arbejde bliver en del af objekterne 3D-scannet og gjort tilgængelige i dynamiske pdf-dokumenter. I pdf-dokumenterne kan brugeren manipulere genstandene på forskellig måde. De kan drejes og zoomes, og lyssætningen kan ændres. Brugeren har mulighed for at lave forskellige tværsnit af genstanden, måle dens forskellige dele og zoome, panne m.m. imens, således at tværsnit, mål, etc. kan ses og bruges fra alle tænkelige vinkler.
Et hurtigt indtryk er, at denne form for tilgængeliggørelse må kunne gøre genstandene brugbare for mange målgrupper. Kunsthåndværkeren, producenten af museumskopier – samt naturligvis forskeren og den studerende, der ikke behøver at have fat i de originale objekter. Genstandene kan nærstuderes i detaljer, uden at det nødvendigvis kræver en tur med Oslo-båden.
Zooniverse er en engelsksproget portal for crowdsourcing. Her transskriberes og tagges på livet løs. Jeg er ikke stødt på noget lignende – af samme omfang – i Norden. Selvom arkivportalen.no har en ansats af noget lignende.
Zooniverse er en stor, fælles indgang eller platform for en lang række “citizen science” projekter. Projekterne drives af flere forskellige institutioner, og platformens samlede tilbud er derfor ikke er bundet til hverken én institution eller institutionstype.
Platformen er efterhånden af ældre dato. Det første tiltag var Galaxy Zoo, som startede tilbage i 2007 – et projekt som handler om at beskrive eller klassificere fotos af galakser og himmellegemer. Siten blev hurtigt populær, og allerede i løbet af det første år havde over 150,000 mennesker bidraget med mere end 50 millioner klassifikationer.
Zooniverse drives af ”Citizen Science Alliance” som udgøres af en række forskere, softwareudviklere og undervisere med interesse i citizen science. Blandt institutioner, som er ”organisationsmedlemmer”, findes bl.a. Oxford, National Maritime Museum og Johns Hopkins universitetet. Alliancens mål er – bl.a. gennem facilitering af distribuerede fællesskaber – at øge forståelsen for videnskab, de videnskabelige processer, samt skabe resultater. I dag rummer Zooniverse mange forskellige projekter, dog med overvægt til det naturvidenskabelige.
Der findes dog også humanistiske/”historiske” projekter, hvoraf det mest kendte nok er “Old Weather“, som drives af National Archives i UK og USA, britisk meterologisk institut, National Maritime Museum m.fl. Målet er transskribering af vejrinformation fra skibes logbøger. Transskriberingen kan være interessant for flere – dels folk med interesse i søfart og skibe (ikke mindst de fartøjer, hvis logbøger indgår). Men resultaterne også fx forskere med interesse i klimaændringer kan benytte data til fx udvikling af klimamodeller og beskrivelse af klimaændringer. Og her vil der være tale om meget “big data”, store datamængder. I dag er ca. 20% af logbøgerne er transskriberet.
Der foregår mange crowdsourcing-projekter idag, især i arkivverdenen, og mange har – skønt forskellige – en række ensartede behov. Der kan typisk være brug for visning af originaldokumenter eller fotos, samt adgang til en række indtastningsfelter, hvis indhold gemmes i en database. I nogle tilfælde kan der også være behov for brugerregistrering. Kunne det, i samarbejde mellem flere institutioner, være muligt at skabe en tilsvarende, fælles platform for citizen science i Danmark. Eller måske en fælles nordisk løsning, som tager udgangspunkt i regionens sproglige og kulturelle fællesskaber. Med mere samlende indgange til crowdsourcingprojekter kunne de enkelte initiativer måske berige hinanden – om ikke andet, så måske i form af udviklerfællesskaber.
Dette indlæg står i gæld til mange gode diskussioner med @runemester
Citizen Science er et centralt begreb for nutidens kulturarvspraksis. I USA bruges betegnelsen Citizen Science til at beskrive fænomenet bag den “crowd” som medvirker aktivt i transskribering, behandling af data, crowdfunding, m.m.
Begrebet er ikke nyt, bl.a. beskrevet i Alan Irwins “Citzen Science” fra 1995, som tager udgangspunkt i relationen mellem forskere og “crowdsourcere”. Ét af de ældste projekter er måske SETI, der startede på nogenlunde samme tid. SETI afsøger universet for elektromagnetisk stråling, tegn på transmissioner eller lignende, der kan tyde på intelligent liv – og at lytte efter eventuelle telefonopkald fra E.T. er en uhyre stor opgave. Derfor var det alvorligt, da USA standsede finansieringen af projektet. Løsningen var crowdsourcing: 1000-vis af mennesker downloadede “datapakker”, behandlede data på egen computer – og sendte de færdige resultater tilbage. Databehandlingen foregik, når den tændte computer stod ubrugt – og vistes som en farverig screensaver.
På National Archives i Washington hedder crowdsourcing-indgangen “Citizen Archivist Dashboard” – en del af Citzen Archivist Project – hvor “borgerdeltagelses”-begrebet også er centralt, og formålet er “promoting public awareness of National Archives records and historical research, by actively engaging citizens to work with primary source documents.”
På dansk taler vi om Citizen Science med ord som “brugerinddragelse” og “crowdsourcere”. Men er det dækkende? “Brugere” og “borgere” er ord med forskellig betydning. En “bruger” er en person, som anvender en given tjeneste – hvorimod en “borger” er et medlem af samfundet, med rettigheder, pligter og ansvar overfor et fællesskab. Har vi brug for et nyt ord?











{kind=link}
{kind=link}